How we built it: Smart Retries
Twenty-five percent of lapsed subscriptions are purely due to payment failures. These unintentional cancellations are called involuntary churn, and they occur for a variety of reasons such as insufficient funds in a customer’s bank account, an expired card number, new card details, or technical problems with the payment.
Reducing involuntary churn is a huge revenue opportunity for businesses: subscriptions that were about to churn for involuntary reasons, but are recovered by Stripe tools, continue on average for seven more months. That’s like acquiring a whole new subscriber. Yet despite the opportunity, many businesses don’t take the steps necessary to limit involuntary churn—often because doing so with in-house resources would be time-consuming and technically complex.
It’s a problem every subscription business faces, yet until recently they’ve had to solve it (or not) on their own. That’s exactly the kind of challenge Stripe’s engineering team likes to tackle. By solving the problem of involuntary churn for subscription businesses that run on Stripe, we can free up a huge amount of bandwidth that they can redeploy to their core product offerings. The entire internet economy is better off as a result.
One of the key challenges to limiting involuntary churn is knowing when to retry a failed payment. If a subscription payment fails, sometimes it makes sense to retry it almost immediately, such as in the case of a technical payment failure. Other times, the optimal time for a retry might be the next day—maybe the customer has replenished their bank account by then—or even the next week, such as when a credit card has expired and a new card needs to be issued.
This type of optimization problem is a perfect fit for machine learning algorithms, which can ingest dozens or more features of a failed payment, match them against patterns generated from historical data, and determine with high probability the best time to try a payment again. Yet doing this, quickly and accurately, involves a lot more than letting an off-the-shelf algorithm loose on a lot of data. It’s a hard engineering challenge that we’ve been working on solving through a tool we call Smart Retries, which predicts the optimal time to retry a failed payment using machine learning algorithms trained on billions of data points across the Stripe network.
As an engineer on Stripe’s Billing team, my job is to help customers recover and retain more revenue. Building Smart Retries required expertise in software engineering, payments, fraud detection, and risk management. It also demanded optimizing ML on large, diverse data sets, and solving challenges like data latency and system performance. In this post, I’ll walk you through the engineering decisions we made that have enabled Smart Retries to recover $9 in revenue for every $1 customers spend on Billing—and the four main lessons we learned throughout the process.
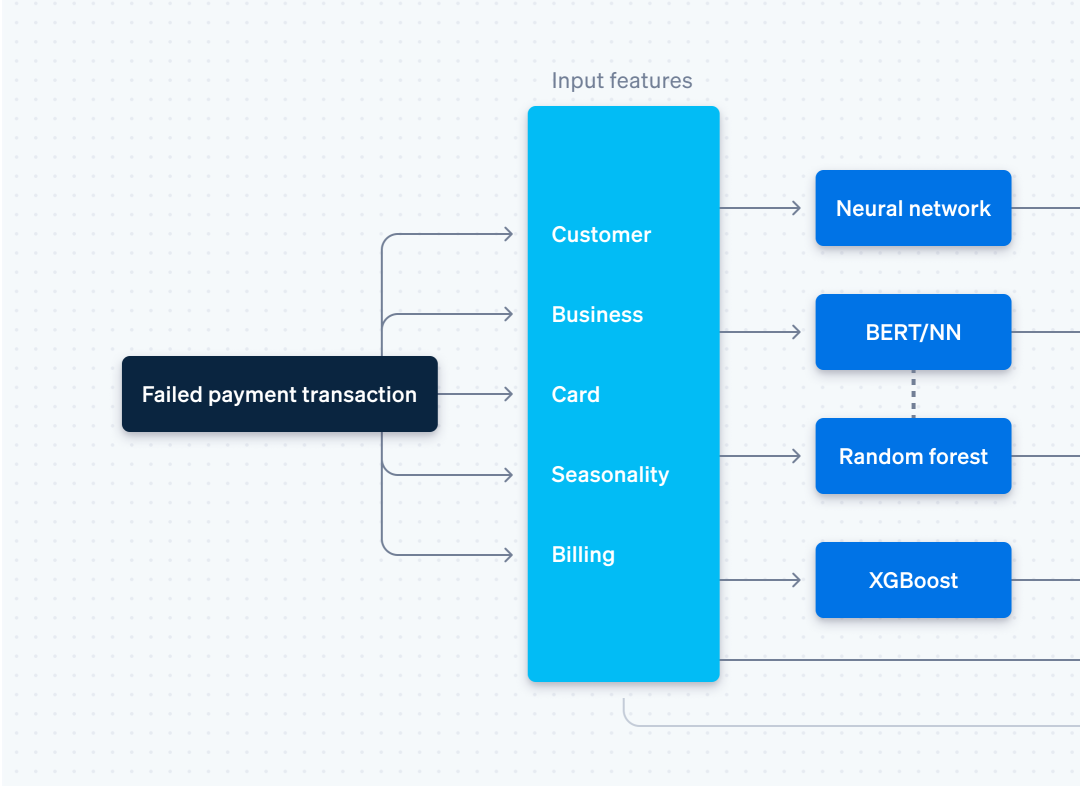
Attributes of a failed subscription payment
Each year Stripe handles payment transactions worth hundreds of billions of dollars for millions of businesses, collaborating with thousands of affiliate banks worldwide in the process. This expansive scope provides us with a set of signals which allow us to understand when and why successful subscription payments go through, and when to retry one that does not. These signals become the more than 500 attributes we use to train our Smart Retries ML model. They fall into a handful of categories:
- Customer attributes, such as their location, pattern of payment, and the overall success rate of their transactions across businesses that run on Stripe can help Smart Retries achieve better success in recovering payment.
- Business attributes, such as industry, currency, and geography, which all affect the optimal retry time. For instance, the optimal time for retrying a payment varies depending on whether or not the customer and the business are located in the same region.
- Payment attributes are invaluable for predicting retry outcomes. These include both the history of successful and failed transactions for a given card and real-time features such as decline codes and messages.
- Seasonality attributes, such as the time of day, day of the week, week of the month, and month of the year—combined with geography, currency, and customer data—play an important role in predictive performance.
- Billing attributes, such as a business’s broader product mix, may have varying retry outcomes and patterns, and understanding how customers with successful payments behave within the product mix is helpful.
Identifying the attributes that matter was more than a brute-force effort. Many of the attributes that play an important role in Smart Retries were identified by our engineers and payments experts, while others arose through a feature engineering process. Yet identifying the right attributes by itself was not enough to make Smart Retries work well. We’ve taken a careful approach over the last few years that has allowed us to amplify the model’s strengths.
Lesson one: Heavy-duty retry models work
Developing a machine learning model almost always involves dealing with a tradeoff between accuracy and speed. Larger and more complex models tend to be more accurate but have higher latency, while more lightweight models have lower latency at the expense of accuracy. Determining which kind of tradeoff made the most sense for Smart Retries hinged on understanding the timescales we had to work with. The best time to retry many failed subscription payments is days into the future. That gives us a lot of freedom to build heavier-duty models with much better accuracy since speed isn’t always our main priority. In 2023, we incorporated this time allowance into an Auto-ML–based ensemble architecture that significantly improved upon our previously deployed XGBoost model.
Ensemble models use the central limit theorem, which says that larger samples will have less variance and converge toward a normal distribution. Adopting the Auto-ML ensemble architecture allowed us to decrease the variance in our output forecasts by merging predictions from multiple state-of-the-art models. This stacked ensemble model addresses the weaknesses in individual model predictions (each of which is left intentionally weak) and harnesses synergies among different base models. The final layer uses ensemble selection to gather the stacker model’s forecasts in a method that considers different individual model weights. This takes a bit more time to execute, but if we’re retrying a payment days or weeks out with greater accuracy, it’s time well spent.
Lesson two: Multimodal data is key to greater precision
In machine learning, embeddings are a useful way to represent higher-dimensional input data in a lower-dimensional space. This provides a scaffold for capturing underlying characteristics and patterns that may be difficult to infer just from the raw numerical inputs. Features like product descriptions, customer location, and subscription characteristics can be combined, using Sentence Transformers, to form these embeddings, which can then be fed into other machine learning models.
Multimodal text and numerical data can be converted into embeddings by leveraging transformers, which map these disparate data types into a shared lower-dimensional space. Text-based features could come from product descriptions and other subscription characteristics, while numerical features might include network decline codes and temporal aspects of failed payments. These combined features capture the nuanced interplay between data from different modalities and enable more accurate predictions. Sentence transformers are one way we form these embeddings. The ensemble stack, described in lesson one, has these transformers built-in as one of its models, which produce outputs that are then fed into subsequent layers in the stack. Essentially, this allows Smart Retries to benefit from multimodal data—not just data in a tabular form (which is traditionally where XGBoost shines). This often leads to higher-precision predictions. For instance, the relevant patterns for a consumer product and its associated card mix are vastly different from the features that matter for retrying a SaaS enterprise subscription, and a model equipped with this insight is invaluable for retry predictions. By combining this feature engineering with constantly improving model architecture, we are able to effectively utilize signals that get richer over time.
Lesson three: Customers want both granular control and high-performance models
The core of Smart Retries is an ML algorithm, but we incorporate it into a flexible system design that allows Stripe customers to customize retry settings in a way that makes the most sense for their business. Smart Retries allows Stripe customers to select the drop-dead day for retries as well as the max-attempts (number of times) to retry the failed payment. They can also select a final action for a subscription or an invoice.
We built a flexible and modern service that provides Stripe customers with more granular settings. Specifically, businesses are no longer restricted to using a single retry setting across all payment failures. A business that offers both B2B and B2C products can split their strategies across products with retry settings that can be optimized for each customer segment. With changing customer mix, businesses can also modify these settings. But before enabling them to do so, we had to make sure we preserved the predictions for previously failed payments, so that the new settings would only affect payments that fail in the future.
Lesson four: Benchmarking data helps both models and customers make better decisions
Giving Stripe customers control over how long and how often to retry failed subscription payments improves retry outcomes. But that flexibility to set retry parameters can pose a dilemma for a Stripe customer, who has to decide how long to allow their churned subscribers to access a product without paying for it.
Stripe data offers a lot of insight into retry strategies, which we share with Stripe customers in the form of an optimal global default setting—a number that reflects what we’ve learned about how to maximize recovered revenue in general while minimizing the time churned customers can use a product for free. But the best time varies with circumstances. For instance, when a payment fails due to insufficient funds from a customer’s debit card, the drop-dead day for retries should at the very least include the customer’s next payment period to maximize a successful retry outcome.
Stripe’s vision for smarter revenue recovery
As a machine learning engineer, I love that my work solves a thorny and little-discussed problem for businesses—and that our customers can focus on their products and customers, knowing we’ve got their payment systems covered. Businesses can activate Smart Retries with a click of a button, and it adds up to substantial revenue improvements for Stripe customers. In one year, on-demand delivery service Deliveroo recovered more than £100 million using Smart Retries in coordination with other Stripe revenue recovery tools (card account updater and Adaptive Acceptance). Or, to take another example, last year Retool—a development platform for building customer software—recovered more than $600,000 in revenue with Smart Retries.
Smart Retries is part of a suite of revenue recovery tools built into Stripe Billing. These features enable customers to monitor and analyze subscription payment failures and recovery rates on a new page in their Dashboard. These new recovery analytics will allow customers to measure the effectiveness of all their recovery efforts in one place, and drill down into trends using downloadable reports directly in Stripe Sigma. We have also released new customizable configurable retries, automated notifications, and configurable invoice and subscription state management. With these features, our customers will be able to define different retry and recovery behaviors to meet their business needs. Customers will also be able to optimize recovery rates using customized retry policies based on billing cycle (monthly vs. annual), and build and manage retry logic for out-of-band payment methods using recovery and retention automations.
To learn more about Smart Retries, Stripe’s other revenue recovery tools, and the churn issues they help solve, read the newly published Stripe guide to churn. If innovating on ML to solve tough, meaningful problems excites you, consider becoming part of our Billing team.
© 2025 Stripay. All rights reserved.