How Stripe’s document databases supported 99.999% uptime with zero-downtime data migrations
In 2023, Stripe processed $1 trillion in total payments volume, all while maintaining an uptime of 99.999%. We obsess over reliability. As engineers on the database infrastructure team, we provide a database-as-a-service (DBaaS) called DocDB as a foundation layer for our APIs.
Stripe’s DocDB is an extension of MongoDB Community—a popular open-source database—and consists of a set of services that we built in-house. It serves over five million queries per second from Stripe’s product applications. Our deployment is also highly customized to provide low latency and diverse access, with 10,000+ distinct query shapes over petabytes of important financial data that lives in 5,000+ collections distributed over 2,000+ database shards.
We chose to build DocDB on top of MongoDB Community because of the flexibility of its document model and its ability to handle massive volumes of real-time data at scale. MongoDB Atlas didn’t exist in 2011, so we built a self-managed cluster of MongoDB instances running in the cloud.
At the heart of DocDB is the Data Movement Platform. Built originally as a horizontal scaling solution to overcome vertical scaling limits of MongoDB compute and storage, we customized it to serve multiple purposes: merging underutilized database shards for improved utilization and efficiency, upgrading the major version of the database engine in our fleet for reliability, and transitioning databases from a multitenant arrangement to single tenancy for large users.
The Data Movement Platform enabled our transition from running a small number of database shards (each with tens of terabytes of data) to thousands of database shards (each with a fraction of the original data). It also provides client-transparent migrations with zero downtime, which makes it possible to build a highly elastic DBaaS offering. DocDB can split database shards during traffic surges and consolidate thousands of databases through bin packing when traffic is low.
In this blog post we’ll share an overview of Stripe’s database infrastructure, and discuss the design and application of the Data Movement Platform.
How we built our database infrastructure
When Stripe launched in 2011, we chose MongoDB as our online database because it offered better developer productivity than standard relational databases. On top of MongoDB, we wanted to operate a robust database infrastructure that prioritized the reliability of our APIs, but we could not find an off-the-shelf DBaaS that met our requirements:
- Meeting the highest standards of availability, durability, and performance
- Exposing a minimal set of database functions to avert self-inflicted issues due to suboptimal queries from client applications
- Supporting horizontal scalability with sharding
- Offering first-class support for multitenancy with enforced quotas
- Providing strong security through enforcement of authorization policies
The solution was to build DocDB—with MongoDB as the underlying storage engine—a truly elastic and scalable DBaaS, with online data migrations at its core.
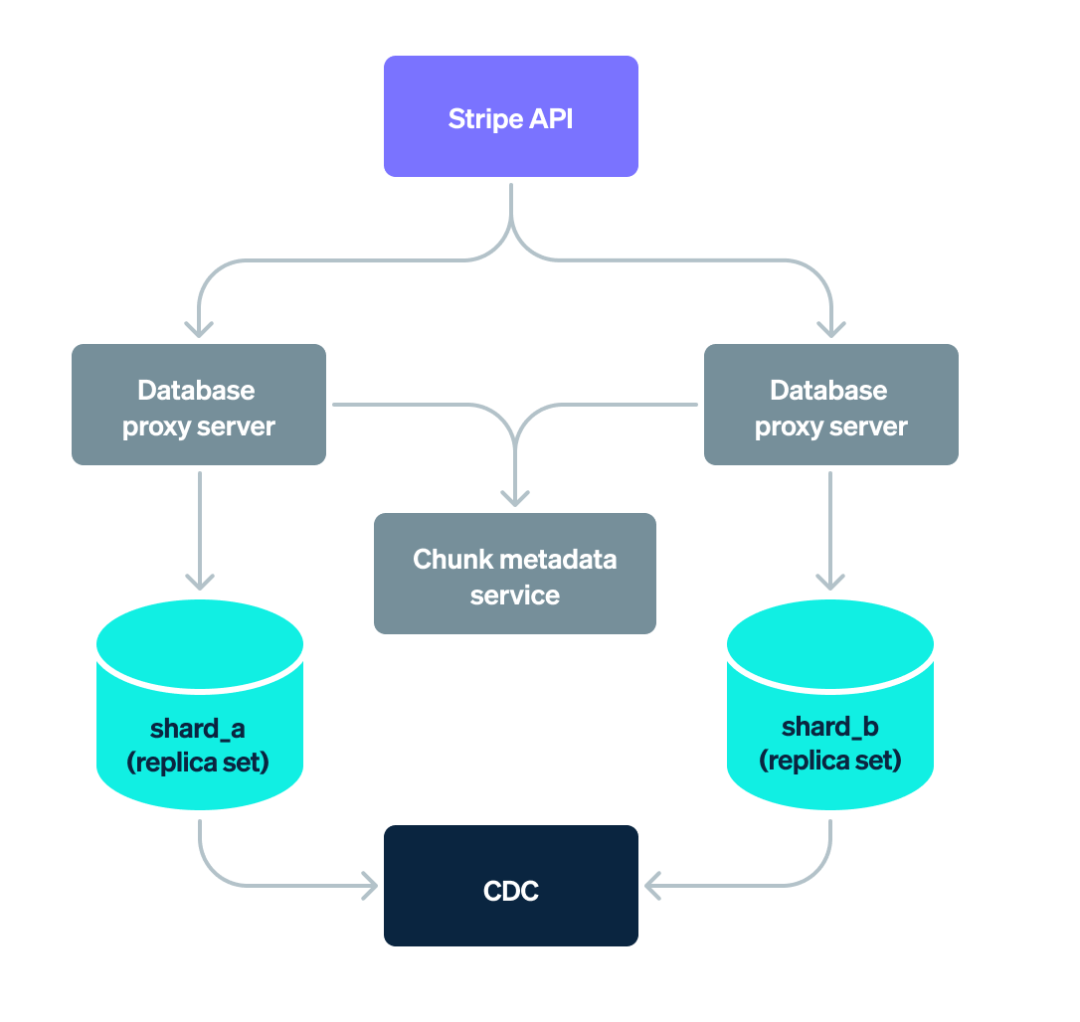
Product applications at Stripe access data in their database through a fleet of database proxy servers, which we developed in-house in Go to enforce concerns of reliability, scalability, admission control, and access control. As a mechanism to horizontally scale, we made the key architectural decision to employ sharding. (If you want to learn more about database sharding, this is a helpful primer.)
Thousands of database shards, each housing a small chunk of the cumulative data, now underlie all of Stripe’s products. When an application sends a query to a database proxy server, it parses the query, routes it to one or more shards, combines the results from the shards, and returns them back to the application.
But how do database proxy servers know which among thousands of shards to route the query to? They rely on a chunk metadata service that maps chunks to database shards, making it easy to look up the relevant shards for a given query. In line with typical database infrastructure stacks, change events resulting from writes to the database are transported to streaming software systems, and eventually archived in an object store via the change data capture (CDC) pipeline.
At the product application level, teams at Stripe use the in-house document database control plane to provision a logical container for their data—referred to as a logical database—housing one or more DocDB collections, and each comprising documents that have a related purpose. Data in these DocDB collections is distributed across several databases (referred to as physical databases), each of which is home to a small chunk of the collection. Physical databases on DocDB live on shards deployed as replica sets that comprise a primary node and several secondary nodes with replication and automated failover.
How we designed the Data Movement Platform
In order to build a DBaaS offering that is horizontally scalable and highly elastic—one that can scale in and out with the needs of the product applications—we needed the ability to migrate data across database shards in a client-transparent manner with zero downtime. This is a complex distributed systems problem, one that is further compounded by the unique requirements of important financial data:
- Data consistency and completeness: We need to ensure that the data being migrated remains consistent and complete across both the source and target shards.
- Availability: Prolonged downtime during data migration is unacceptable, as millions of businesses count on Stripe to accept payments from their customers 24 hours a day. Our goal is to keep the key phase of the migration process shorter than the duration of a planned database primary failover—typically lasting a few seconds, and in line with the retry budget of our product applications.
- Granularity and adaptability: At Stripe’s scale, we need to support the migration of an arbitrary number of chunks of data from any number of sources to target shards—with no restrictions on the number of in-flight database chunk migrations in the fleet, and no restrictions on the number of migrations any given shard can participate in at any point in time. We also need to accommodate the migration of chunks of varying sizes at a high throughput, as several of our database shards contain terabytes of data.
- No performance impact to source shard: When we migrate database chunks across shards, our goal is to preserve the performance and throughput of the source shard to preclude any adverse impact on performance and available throughput for user queries.
To address these requirements, we built the Data Movement Platform to manage online data migrations across database shards by invoking purpose-built services.
The Coordinator component in the Data Movement Platform is responsible for orchestrating the various steps involved in online data migrations—it invokes the relevant services to accomplish each of the constituent steps outlined below:
Step 1: Chunk migration registration
First we register the intent to migrate database chunks from their source shards to arbitrary target shards in the chunk metadata service. Subsequently, we build indexes on the target shards for the chunks being migrated.
Step 2: Bulk data import
Next, we use a snapshot of the chunks on the source shards at a specific time, denoted as time T, to load the data onto one or more database shards. The service responsible for performing bulk data import accepts various data filters, and only imports the chunks of data that satisfy the filtering criteria. While this step appeared simple at first, we encountered throughput limitations when bulk loading data onto a DocDB shard. Despite attempts to address this by batching writes and adjusting DocDB engine parameters for optimal bulk data ingestion, we had little success.
However, we achieved a significant breakthrough when we explored methods to optimize our insertion order, taking advantage of the fact that DocDB arranges its data using a B-tree data structure. By sorting the data based on the most common index attributes in the collections and inserting it in sorted order, we significantly enhanced the proximity of writes—boosting write throughput by 10x.
Step 3: Async replication
Once we have imported the data onto the target shard, we begin replicating writes starting at time T from the source to the target shard for the database chunks being migrated. Our async replication systems read the mutations resulting from writes on the source shards from the CDC systems and issue writes to the target shards.
The operations log, or oplog, is a special collection on each DocDB shard that keeps a record of all the operations that mutate data in databases on that shard. We transport the oplog from every DocDB shard to Kafka, an event streaming platform, and then archive it to a cloud object storage service such as Amazon S3. (If you want to learn more about oplog, this is a helpful primer.)
We built a service to replicate mutations from one or more source DocDB shards to one or more target DocDB shards using the oplog events in Kafka and Amazon S3. We relied on the oplog events from our CDC systems to ensure that we didn’t slow user queries by consuming read throughput that would otherwise be available to user queries on the source shard, and to avoid being constrained by the size of the oplog on the source shard. We designed the service to be resilient to target shard unavailability, and to support starting, pausing, and resuming synchronization from a checkpoint at any point in time. The replication service also exposes the functionality to fetch the replication lag.
Mutations of the chunks under migration get replicated bidirectionally—from the source shards to the target shards and vice versa—and the replication service tags the writes it issues to avert cyclical asynchronous replication. We made this design choice to provide the flexibility to revert traffic to the source shards if any issues emerge when directing traffic to the target shards.
Step 4: Correctness check
After the replication syncs between the source and target shard, we conduct a comprehensive check for data completeness and correctness by comparing point-in-time snapshots—a deliberate design choice we made in order to avoid impacting shard throughput.
Step 5: Traffic switch
Once the data in a chunk is imported from the source to the target shard—and mutations are actively replicated—a traffic switch is orchestrated by the Coordinator. In order to reroute reads and writes to the chunk of data being migrated, we need to first: stop the traffic on the source shard for a brief period of time, update the routes in the chunk metadata service, and have the proxy servers redirect reads and writes to the target shards.
The traffic switch protocol is based on the idea of versioned gating. In steady state, each proxy server annotates requests to DocDB shards with a version token number. We added a custom patch to MongoDB that allows a shard to enforce that the version token number it receives on requests from the proxy servers is newer than the version token number it knows of—and only serve requests that satisfy this criterion. To update the route for a chunk, we use the Coordinator to execute the following steps:
- First, we bump up the version token number on the source DocDB shard. The version token number is stored in a document in a special collection in DocDB, and all reads and writes on the chunk on the source shard are rejected at this point.
- Then, we wait for the replication service to replicate any outstanding writes on the source shard.
- Lastly, we update the route for the chunk to point to the target shard and the version token number in the chunk metadata service.
Upon completion, the proxy servers fetch the updated routes for the chunk and the most up-to-date version token number from the chunk metadata service. Using the updated routes for the chunk, the proxy servers route reads and writes for the chunk to the target shard. The entire traffic switch protocol takes less than two seconds to execute, and all failed reads and writes directed to the source shard succeed on retries.
Step 6: Chunk migration deregistration
Finally, we conclude the migration process by marking the migration as complete in the chunk metadata service and subsequently dropping the chunk data from the source shard.
Applications of the Data Movement Platform
The ability to migrate chunks of data across DocDB shards in an online manner helps us horizontally scale our database infrastructure to keep pace with the growth of Stripe. Engineers on the database infrastructure team are able to split DocDB shards for size and throughput with a click of a button, freeing up database storage and throughput headroom for product teams.
In 2023, we used the Data Movement Platform to improve the utilization of our database infrastructure. Concretely, we bin-packed thousands of underutilized databases by migrating 1.5 petabytes of data transparent to product applications, and reduced the total number of underlying DocDB shards by approximately three quarters. We also used the Data Movement Platform to upgrade our database infrastructure fleet by fork-lifting data to a later version of MongoDB in one step—without going through intermediate major and minor versions with an in-place upgrade strategy.
The database infrastructure team at Stripe is focused on building a robust and reliable foundation that scales with the growth of the internet economy. We are currently prototyping a heat management system that proactively balances data across shards based on size and throughput, and investing in shard autoscaling that dynamically responds to changes in traffic patterns.
At Stripe, we’re excited to solve hard distributed systems problems. If you are too, consider joining our engineering team.
© 2025 Stripay. All rights reserved.